SlackのAPI仕様が変わっててうまく動かなくなってたから直した channels.history->conversations.history
目次
以前
couraeg.hatenablog.com
こんな感じでSlack(channels.history メソッド)をGASでスプレッドシートに簡易の問題集を吐き出せるスクリプトを作ったんだけど(ずっと放置してたけど)
知らない間にAPIの仕様が変わっていたようで動かなくなっていた。
ということで動くようにした。
ざっと結果を先に。
・とりあえずうまくいく。
・channels.historyは非推奨だからconversations.historyを使おう。
・conversations.historyは親のメッセージしか読まないから、スレッドを掘りたかったらconversations.repliesも合わせて使おう。
ということでとりあえずいい感じになった。
発生している事象&トラブルシュート
ボタンをクリックして、スクリプトを実行。シートにSlackの問題を書きだすはずが・・・
 gyazo.com
gyazo.com
とまぁ。スクリプトは正常に動いてるけど全然吐き出されない。なんぞ。
おおよそ辺りはついていて、
 gyazo.com
gyazo.com
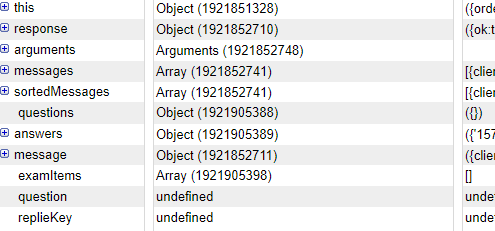
この辺(returnのところで)をブレイクしてみる。仕組みとしてはAPIで受け取ったレスポンスから
Questions(スレッドの開始)とそれにつながるAnswers(スレッドに紐づいてるメッセージ)
を振り分けている想定。
 gyazo.com
gyazo.com
Questionsが空っぽなので、まるで問題が生成されていない。。。
IsQuestionの実装は単純で
function isQuestion(message) { return "replies" in message; }
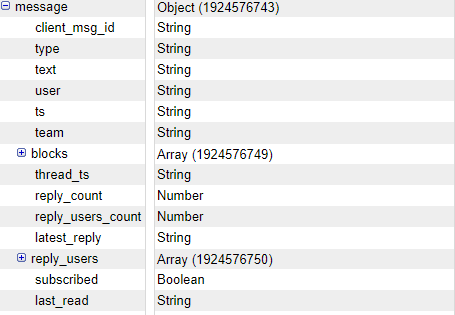
だ。なので、repliesさえちゃんとあればまともに動くはず。もしやと思ってmessageの中を開けてみると
 gyazo.com
gyazo.com
ご覧のありさまで。パラメータがなくなっている様子。
ひとまずchannels.historyメソッドの公式を見てみましたが・・・それらしきパラメータはresponseにはなさそうです・・・
api.slack.com
変わりにreply_countというパラメータが返ってきてます。こっちも公式には乗っていませんが、ひとまずこれを使ってみることにしました。
latest_replyにはTSが返ってきているのでこれも使えそうです。そのように変更してみます。
こんな感じに直します。
/** 試験データとして扱いやすいように加工して返却する。 */ function convertExamItems(response) { var messages = fillExamMessages(response); var sortedMessages = orderByTimeStampeAscending(messages); Logger.log("formatExamItem:sortedMessages{" + sortedMessages + "}"); // timeStampをキーとして、問題(リプライがあるか)と回答で分ける。 var questions = {}; var answers = {}; for(i in sortedMessages) { var message = sortedMessages[i]; if(isQuestion(message)) { questions[message["ts"]] = message; } else { answers[message["ts"]] = message; } } var examItems = []; for(key in questions) { var question = questions[key]; //var replieKey = question["replies"][0]["ts"]; var replieKey = question.latest_reply; question["answer"] = answers[replieKey]; examItems.push(question); } return examItems; } function isQuestion(message) { //return "replies" in message; return message.reply_count > 0; }
試しに実行しました。
 gyazo.com
gyazo.com
とりあえずそれっぽく動くようになりました。あっていたらしい。
ところで、公式に不穏な記述があるぞ・・・
よく見るとAPIのレスポンスにも書いてあるんですが、いまつかっているAPIは非推奨なようで。。。
conversations.history
をつかっちゃいなよ!
みたいなことが書かれています。ということでとりあえず呼び出すAPIを変えてみます。
 gyazo.com
gyazo.com
あばばばばば。。。ということで公式見ながらデバッグします。
前と同じ場所にブレイクを張って見ます。
 gyazo.com
gyazo.com
今度はAnswerが一つもありません。母体となるmessagesのほうを見てみましょう。
 gyazo.com
gyazo.com
どうやら2件しか返ってきて稲用です。QとAで2組あるので、4件来る想定ですが。
どうやらQの部分しか取得できていないようです。公式説明を読んでみます。
conversations.repliesをつかう。
api.slack.com
残念ながらreplyに関する記述はここからは読み取れませんでした。観念してググって見ます。
dev.classmethod.jp
の中に答えがありました。
conversations.repliesを使えばよいようです。公式の方もみてみます。
api.slack.com
This Conversations API method returns an entire thread (a message plus all the messages in reply to it), while conversations.history method returns only parent messages.
ということで、こっちにはおもいっきりconversations.historyでは親しかとれないよ。と書いてました。うまく組み合わせて使う必要がありそうです。
conversations.repliesはthread_idの指定が必要です。なので、まとめて一気にとるような使い方ができません。
histolyでスレッドを特定して、内容はrepliesでとるようにしてみます。
function cannelReplyURL(thread_ts) { var url = "https://slack.com/api/conversations.history"; url += "?"; url += "channel=" + channelID; url += "&" url += "ts=" + thread_ts; Logger.log("cannelReplyURL:{" + url + "}"); return url; } /** * UrlFetchAppを使って結果を返す。 * @param {string} Request URL * @param {Object} Request Option Parameters * @return {Object} Get Request Response Json Object */ function fetchApp(url) { var response = UrlFetchApp.fetch(url, token); var parsedResponse = JSON.parse(response.getContentText()); Logger.log("getRequest:{" + parsedResponse + "}"); return parsedResponse; } /** 試験データとして扱いやすいように加工して返却する。 */ function convertExamItems(response) { var messages = fillExamMessages(response); var sortedMessages = orderByTimeStampeAscending(messages); Logger.log("formatExamItem:sortedMessages{" + sortedMessages + "}"); // timeStampをキーとして、問題(リプライがあるか)と回答で分ける。 /* var questions = {}; var answers = {}; for(i in sortedMessages) { var message = sortedMessages[i]; if(isQuestion(message)) { questions[message["ts"]] = message; } else { answers[message["ts"]] = message; } } var examItems = []; for(key in questions) { var question = questions[key]; //var replieKey = question["replies"][0]["ts"]; var replieKey = question.latest_reply; question["answer"] = answers[replieKey]; examItems.push(question); } */ var examItems = []; for(i in sortedMessages) { var apiResponse = fetchApp(cannelReplyURL(sortedMessages[i].thread_ts)); var question = apiResponse.messages[0]; question["answer"] = apiResponse.messages[1]; examItems.push(question); } return examItems; } /*function isQuestion(message) { //return "replies" in message; return message.reply_count > 0; } */
fetchAppはもともとあるものを再利用。なんだかよくわからないループもすっきりしました。バッチりです。
SQLのたてもちよこもち。たてもちからよこもちへ
SQLを触っているとよくでてきますが。そのたびにGoogle先生に問い合わせをしているような
気がしています。ということで定着させるためにも一回まとめることにしました。
とりあえず検索
SQLもテーブル構造も出ていてとてもよくまとまっているので、このURLを覚えておくだけで事足りるのでは・・・
dev.classmethod.jp
定着が目的なので、自分でもやってみます。
検証環境
AWS RDS(SQL Server Express Edition)
SSMS v18.4
を使いました。
AWSでSQL Serverをたてて、SSMSで接続するシンプルな形です。
テーブル
こんなノリのやつを用意しました。
 gyazo.com
gyazo.com
ステータス事の値を横に持ちたい。ということはあるでしょうから、こんな感じでしょう。
とりあえずくっつけてみる。
WINDOW関数もなく、そのまま「えいや!」でくっつけるとこんな形のSQLになるかとおもいます。
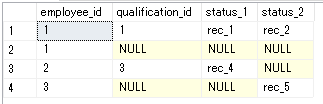
select emp.employee_id, st1.qualification_id, st1.value as status_1, st2.value as status_2 from employee_qualification emp left join qualification as st1 on emp.qualification_id = st1.qualification_id and st1.status = 1 left join qualification as st2 on emp.qualification_id = st2.qualification_id and st2.status = 2
実行結果は
 gyazo.com
gyazo.com
こんな感じで。性能がどうのこうのなければ、このままでもいいんでないかと思います。
せっかくなので、プロファイル情報も取得します。
「SETSTATISTICS PROFILE ON」で取得を有効にすると
 gyazo.com
gyazo.com
こんな形で取得できます。TotalCostは「0.0104844」
実行計画も以下の通りで。
 gyazo.com
gyazo.com
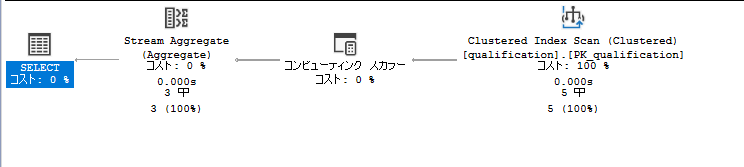
JOINをしてるので当然かもしれないですけど、やたらとNastedLoopsがでてきます。
ただただ横持ちを取りたいだけなのに、なんだかこれはいただけない感じがします。
いまはステータスが2つだけなのでいいですが。4つ5つとなった時にこれは無駄なことをしている感じが大きいです。
ということでいい感じにしていく。
今回はRow_Number等でとる必要がなさそうです。Statusわかっているから
まずは横持ちのテーブルぶぶん
select st.qualification_id, max(case st.status when 1 then st.value else '' end) as value_st1, max(case st.status when 2 then st.value else '' end) as value_st2 from ( select qualification_id ,status ,value from qualification ) st group by st.qualification_id
 gyazo.com
gyazo.com
実行計画もいい感じに落ち着いてます。これをそのまま先ほどのクエリに結合していきます。
こんな感じかと。
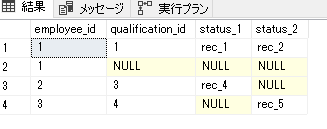
SET STATISTICS PROFILE ON select emp.employee_id, st.qualification_id, st.status_1 as status_1, st.status_2 as status_2 from employee_qualification emp left join ( select st.qualification_id, max(case st.status when 1 then st.value else null end) as status_1, max(case st.status when 2 then st.value else null end) as status_2 from ( select qualification_id ,status ,value from qualification ) st group by st.qualification_id ) st on emp.qualification_id = st.qualification_id
実行結果は同じようです。ここがずれていたら意味ないですからね。
 gyazo.com
gyazo.com
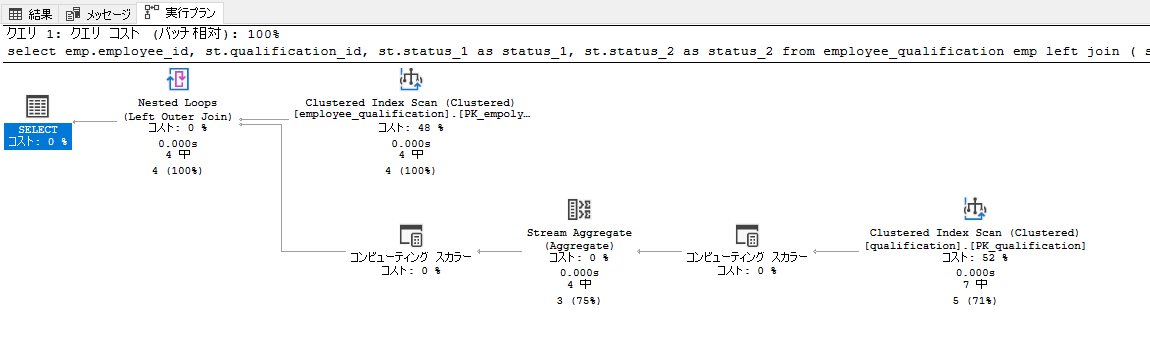
コストの方もよいほうに収まりました(0.00686062)
 gyazo.com
gyazo.com
実行計画も見ておきましょう。
 gyazo.com
gyazo.com
コンピューティングスカラーは気になりますが・・・気にしていたループの本数が減りました。やったね。
このままでも大分いい感じですが、今後のメンテナンス(出したいステータスが増えたときに)
そこそこ厄介なので、以下のようにしておきます。
select emp.employee_id, st.* from employee_qualification emp left join ( select st.qualification_id, max(case st.status when 1 then st.value else null end) as status_1, max(case st.status when 2 then st.value else null end) as status_2 from ( select qualification_id ,status ,value from qualification ) st group by st.qualification_id ) st on emp.qualification_id = st.qualification_id
これで単に必要なステータスが増えた場合でも、一か所修正すればOKとなります。
めでたしめでたし。欲をいえばもう少しわかりやすい位置に移動したいですが、今回はここまでとします。
データって一口に言うけど意識しないとまずいのでは
こんばんみ。AWSの勉強をしていてどうにも「データ」を「データ」のまま適当に認識して取り扱うと、
さっぱり理解が進まない気がしているの自分用に少し整理してみました。その他関連用語が多いので使いどころを含めて。
完全に個人の感覚なのであれですが。
目次
なにが気になったのか?
冒頭のとおり「データ」ってなんじゃ?という疑問。
データといっても、その性質によって名前がつけられています。
・ストリーミング
・キャッシュ
・記録
雑に分けてもこんな感じ。オンプレミスであれば、基本的にPCのメモリかもしくはSSDに打ち込まれるので、
開発する上では特に意識してこなかったんだけど、AWSサービスはインフラに近いところから選定が必要なので、この辺をほっておくとどうにもこうにも立ち行かず。
ちょっと一旦まとめてみようかいね。
「データ」が共通的に持っている性質
・データ構造
・タイムスタンプ
この二つは普遍的で必ず持っている。データ=情報といっても差し支えないかもしれない。
ある特定の時間(タイムスタンプ)における、特定のデータの抽出(データ構造)に名前をつけたものをデータと読んでいる。
Excelファイルもデータ「Excelデータ」、日次の感情や思い出などの記録は「日記」であったり。ここまではそらそうだ間があってあんまりではある。
この辺りは上記「記録」と記述しているが、データの基本的な形となる。
データ種別の判断
データ種別の判断は以下のことで決まっている。
・生存期間
ポイントはデータそのものに生存期間の属性は持っておらず、データを取り扱う方が勝手に決めている。
なので、同じデータ構造、タイムスタンプを持つ「データ」でも取り扱う側からすると「キャッシュ」であったり「記録」であったりする。
ストリーミング
そもそもデータではない。と思っている。ストリーミングにもデータ構造は持っているが、タイムスタンプの形が異なる。
タイムスタンプはその瞬間を切り取っているが、ストリーミングでは永続的に流れ続けている。データの連続がストリーミング。
そのくせにストリーミングデータ。なんていうからタチが悪いなぁなんて思ったりもする。一つのストリーミングは同じデータとして扱うが、
ストリーミングから切り取った一部のデータは同じデータとしては扱はない。同じデータ構造は持っているが。
1つの動画であれば、動画は「開始、終了」を属性に持つデータ構造の「データ」ではあるが、あるタイミングの動画は動画と言わず、
「静止画」というと思う。時間がずれれば「別の」静止画としてあつかう。静止画ももちろんデータ構造を持っている(RGBとか、まぁそのた)
キャッシュと記録
生存期間が極端に短いものを「キャッシュ」という。どの程度短いかはデータを取り扱う側に委ねられる。
1日以上保持するものを「キャッシュ」ということは少ないかもしれないが、それでも場合によりキャッシュと言うことはある。1年だとどうかはわからないが。
キャッシュにはもう少し使う側のイメージによるものがある。
・アクセシビリティ
キャッシュの目的は「再利用」にあるので、データを一度保存した後にどこからか「利用」することが前提となる。
「記録」についても再利用は発生することもあるが、キャッシュを用いる場合は「記録」とするよりも「高速」にアクセスすることを求める場合が多い。
「記録」にするまえのデータを「キャッシュ」と呼ぶこともある。
「記録」から別のElastiCacheなどのメモリに展開したものを「キャッシュ」と呼ぶこともある。
dynamoDBなどのストレージに「記録」をしないデータも「キャッシュ」と呼ぶことがある。
いずれもこれは生存期間によって判断しているためで「キャッシュ」をS3などのストレージなどに保存して永続化したタイミングで「記録」となる。
ストリーミングで吐き捨てたデータについて「キャッシュ」と呼ぶことはないが「記録」の判断のためにストリーミングからデータとして取り出すことを
「キャッシュ」する。とは言うかもしれない。
同時編集からの観点
ストリーミング、およびキャッシュを複数のアカウントから意識的にアクセスすることは基本的にはない。同時編集を行う場合「記録」であることがほとんであろう。
したがって同時編集を意識しないといけないのはストレージサービスである
右記urlより、 AWS が提供するクラウドストレージサービス|AWS
S3
EBS
EFS
のこの辺りは抑えておきたい。S3、EFSは並列の読み込みに耐えうるが、EBSは向いていない。
その他は公式QAを参考にされたし
aws.amazon.com
また、ストレージサービスではないがデータの保管場所という観点では各種DBサービスも候補に上がってくる。
(キャッシュという意味ではSQSも近いものがあると思うが)
DBの比較についても公式を
AWS が提供するクラウドデータベース | AWS
キャッシュが曲者
基本的にキャッシュが全てをややこしくしている。キャッシュという観点でいけば、
インメモリに展開しているEC2とELBのスティッキーセッションでも構成なども上がってくる。
完全にクラウドのメリットを享受できるような構成ができればいいが。状況によりそうもいかない時もあるので、手段はなるべく多くしっておいて損はなさそう。
キャッシュについては本当にいろんなところに保管できるので、その時のベストというのを理解するのがなかなかしんどいなぁと感じる。
こんなところか?「データ」の切り口からAWSざっと眺めてみたけど、この方が記憶に定着しやすいかな。
セッションとか、ログイン情報とか。データ構造による切り口で攻めてみるのもありかな。
S3のイベント通知でSNSに通知を飛ばしてみる
はろーはろー。こんばんみ。
お祭り期間ではあるんですが、ちょっと思いついたことをやりたくなってしまったのでそっちを優先しました。
目次
とりあえずできたんか?
掲題の件、できもうした。
SNSのサブスクリプションに設定してある、私の携帯へSMS通信がきっちり届きました。
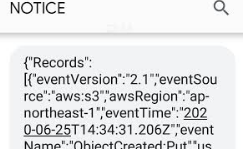 gyazo.com
gyazo.com
とどきましたが。これじゃ何が何だかなので。このままではいけませんね。
構成
S3 → ファイルアップロード → SNSトピック → SMSメッセージ
の流れ。AWSで何かしようと思うと、たくさんサービスが現れてくるので慣れないと戸惑いますが。
ちっさくちっさく作っていくと少量でいけたりするので良いですね。
作業手順
SNSトピックを作る。
名前はご自由に。緊急通報のRSSでも受け取って遊ぼうかなーと思っていたのでそんな感じのトピック名になっています。
S3からの通知を受け取るにはデフォルトのポリシー設定ではたりません。
以下のようなポリシーを追加してやる必要があります。
{
"Sid": "example-statement-ID",
"Effect": "Allow",
"Principal": {
"Service": "s3.amazonaws.com"
},
"Action": [
"SNS:Publish"
],
"Resource": "arn:aws:sns:Region:account-id:topic-name",
"Condition": {
"ArnLike": { "aws:SourceArn": "arn:aws:s3:::bucket-name" },
"StringEquals": { "aws:SourceAccount": "bucket-owner-account-id" }
}buckecName,AccountIDなどは調整が必要です。
※S3のHowToを参考に貼っておきます。
docs.aws.amazon.com
通知確認のために、一緒にサブスクリプションも作っておくと良いでしょう。
S3バケットのイベント設定をする。
バケットを作ってプロパティタブからイベントを選んで設定していきます。
prefix、Suffix等オブジェクトの情報である程度フィルタがかけられるようですが、今回は無視しています。
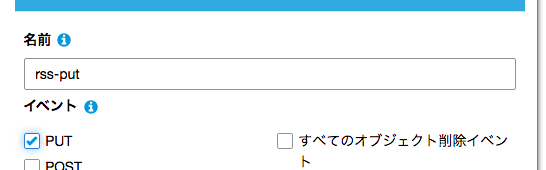 gyazo.com
gyazo.com
前述のポリシー設定がうまく言っていないと、保存時に以下のようなエラーがでます。再度確認してみてください。
 gyazo.com
gyazo.com
発火するか
最後にバケットに適当なオブジェクトを投げ入れて通知が飛ぶか確認してみます。
結果は前述の通り、なんか帰ってきます。Goodですね!
オンデマンドセッション店回り感想(Day6)
本当はDay7。昼休みに書き溜めたものを下書きに上げ忘れてて「まーいいか。」の精神で
機能はアップできていなかった。ということで本日もお祭りを見ていく
1日目と同様、念のため。利害関係はありません。内容を避難するようなものでもありません。
アップするつもりで視聴する。アップするつもりでざっとまとめる。今回の記事の意図としてはそんなところです。
目次
- お祭り会場① DE:CODE
- ゼロトラスト Deep Dive 間違いだらけのリモートワーク セキュリティ
- Azure ならこうする、こうできる! ~ AWS 技術者向け Azure サービス解説 de:code 2020 Edition ~
- 会場② DEVELOPERS.IO 2020
- まっとめ。
お祭り会場① DE:CODE
ゼロトラスト Deep Dive 間違いだらけのリモートワーク セキュリティ

安心安定のVPNという幻想。ゼロトラストと実は相反する。
アクセス元の識別→身元の確認認証→認可
認証と認可はだいぶ理解できてきた。
信頼レベルに応じて、アクセス制御をする。本人でも信頼レベルが落ちるというはすごい。
ふむ。これAWSでしようと思ったら、
認証にlambdaを介在させて、ポリシーを差し替えるような形になるんだろうか。
aws.amazon.com
公式の記事があった。うーん。認証はいける気がするが、認可の柔軟性はデフォルトであまいのかなぁ。
Azure ならこうする、こうできる! ~ AWS 技術者向け Azure サービス解説 de:code 2020 Edition ~
decode20-vevent.cloud-config.jp
よい。クラウドサービスの違いを見るということ。何がやりたいの?からスタートしよう
クラウドバイリンガル。AWSも一つの手段だし、手段は多いほうがいいのは納得。そして
それらを使いこなせるならすごい「価値」だとおもう。
さて、あーんまりAWSの話はでてこなかったな。冒頭でも言っている通り、サービスそのものを比較してもしょうがないからだろう。
というところで。AWSと比較してもらったほうが理解するには楽だったりするかなーとおもったけど、全体的にAzure概要的な内容だった。
半分ぐらい。あとは飛び飛びでみて途中で視聴をやめてしまった。
会場② DEVELOPERS.IO 2020

まっとめ。
よくわからなくても毎日。休まず(休んだが)見ていると違う。
ついでに「いまのオンプレなどうする」みたいなことを通勤道中で考えるようになった。
考えてわからないから答えってのはすぐに見つからないのでFBとしては弱いのだけど、ちゃんと公式をおっていったり、
先人たちの記事を見れば追いきれる。いい時代だなぁ。。。
オンデマンドセッション店回り感想(Day5)
月曜が始まってしまったのであいもかわらず放出されつづけるセッションを追っていきます。
1日目と同様、念のため。利害関係はありません。内容を避難するようなものでもありません。
アップするつもりで視聴する。アップするつもりでざっとまとめる。今回の記事の意図としてはそんなところです。
目次
本日のお祭り会場① Developers.IO 2020 connect
ついに来た!Amazon Detectiveでセキュリティインシデントの調査がちょー捗るからまずやってみよう
インシデント調査が超捗る。とはいいねいいね。
NISTの話が出ていた。
https://www.manageengine.jp/solutions/nist_publications/nist_csf/lp/
なかなかえぐいぜ。セキュリティはこの上で更新も頻繁なので、真面目にやるとこれだけで時間食われますね。
ログ調査を自動で吸い込んでくれるのはいいなぁ。インシデントもそうなのかもしれないけど、
エラーログ等攻撃的な不具合検知に使えないだろうか。
GuradDutyがそもそも強い感じがする。誤検知も考えるとネットワーク周りを触った時は確認したほうが良さそうだなぁ。
誤検知にまみれると本体が見えなくなるし。
1日目だか2日目にみたGoatと組み合わせて遊ぶのが学習には楽しそう。
早朝に見る内容にはちょっと重かったけども。朝だから頭も元気だったので、セーフだったかもしれない。
外に出れないこんなご時世だからこそ、AWS MediaServicesによるライブ配信入門
youtu.be
ピンあんどポイントな内容です。
ライブ配信って身近ではあるんだけど、裏の動き全然わからなくていい勉強になった。
「AWSで構築する理由」ちゃんとあるかね。という話はとてもいいなと思いました。
焦点を絞ってるからこそのボリュームを感じるセッションでした。ちょっとだけMediaServices。わかるようになりました。
まとめ
これで6/16配信分はひとまず見切ったはず。見切っただけ。
全部無料でこのクオリティってのがね。ありがたく視聴させていただきます。せっかくみたんだから今後に活かせるといいなぁ
行かせないといけんよね。そんなかんじ。
お祭り会場② Microsoft DE:CODE2020
Office365
Teams。
www.microsoft.com
なるほど。これに限らず、こーゆーのなんていうんだ?
ワークサービスというか機関部分というか。選択肢が多いのはうれしい。しかし業務で実際に選定されるのはどれだろうか。
各社特色があっていいのだけれど、いろいろ使うようになるのはつらかったりつらくなかったり(比較できるおかけで改善点が見つかったりはするかな)
いろんなIDE渡り歩くような気分で、なるべくデフォルトから離れたくなくなるのは私だけなのだろうか。
いやーしかし。市長普通にでてくるんだよな。最近。ご時世。すばらしい。
というかこの市長のはなしすごく貴重というか、いい意見だと思う。これだけでもみてよかったなぁと思った。
あんまり、普段仕事をしていてエンドユーザの声って聞きにくいんですが(クレームは間接的に届くけど)
大事ですよね。やっぱり使ってくれる人の意見というのは。
セキュリティオーバービュー
セキュリティマネジメント
https://it.impress.co.jp/articles/-/11116
SecurityPosture ゼロトラスト、Modern SOC
単語はなんとか拾えたが。。。これは他の詳細なセッションをみろということだな。
別々の会場でセキュリティの話するんだもんなぁ。一口にセキュリティといっても考えないといけない範囲は広いくて、
私は「セキュリティ」と一口にいってしまうレベルではあるんですけど。
セキュリティは基盤なので、セキュリティがあってこそ開発ができる。普段は邪魔ではあるんだけど。
邪魔をしないように相互に良い影響があるといいねぇなんて。そーゆー感じになってきてるかなーと思います。最近のセキュリティ。
家系ラーメンがめちゃくちゃ食べたい。食べたいから作ってみたらなんか違う感じになった。
こんばんみ。ラーメン好きですか?私はめちゃくちゃ好きです。
というよりジャンクフード全般が好きで、時々無性に食べたくなります。
とくに、東京で生活していた折によくくってたラーメンが非常に食べたいですが、岡山在住のみではなかなか厳しい。
(1週間出張とかないかなぁ・・・)
tabelog.com
濃厚オブ濃厚。辛いまであるレベルで濃厚です。確実に体にダメージを与えてきそうな味ではあるんですが、
くせになるんですね。はー食いたい。ということで思い出しながら家にある食材で作ってみようということで頑張ってみました。
材料
どうせすぐに食べたくなってしまうので、
材料は手に入りやすく安価であること。また加工が楽であるところがポイントになります。
(この辺はそうでないなら店にいくしな。ということで)
・もやし、刻みネギ(ここは好み)
・牛豚ミンチ
・ニンニクチューブ
・鶏ガラスープのもと
・コンソメスープのもと
・醤油
・砂糖
・塩
・冷凍うどん
だいぶ謎なアイテムもありますが、1から全部近所のスーパーで集めても1000円切るんじゃないですかね。
調理です。
とりあえず具材、タレ、その他を集めます。こんかいはもやしだけなんで、茹でるだけっすね。
こんな感じ。
 gyazo.com
gyazo.com
簡単ですね。


実食。フィードバック
とりあえず子供2人は満足いただけた様子。奥様にも好評だったけどパンチが足りないとか塩が足りないとか言われた。
実際僕の方も「にたような味はするけど、なんか違うなこれ。。。」そんな感じ。美味しい。普通に美味しいけど
「はぇー身体にわっるー。けどうっめぇぇぇええええ!!!!」ではない。「あっ。うま。うんうん。おいしいおいしい」そんな感じ。
敗因を考えるにだいたい以下だと思う。
スープの煮込みが甘い。
そもそも煮込んでないのだけれど。だいたい家系ラーメンのスープってトロトロ、ドロドロしてるんだけど。
作ったやつはサラサラしてた。水分とミンチの割合をミスってたのかもしれない(ミンチ自体も加熱すると水分でるしね)
次はもうちょと水分をコントロールして作ってみることにする。
ニンニク感が弱い。
最後にチューブニンニクを放り込む形で再現したのだが。
効いてるところの再現度は高かったように思う。タレ作成時に醤油が不足していて塩の量をミスってたのもあり、
ニンニクのパンチがないのは致命的だったかもしれない。それでも美味しかったのだけど。
つぎは1球つかう勢いで刷り込んで見ることにする。
何がどうあっていい感じに再現しようとしたか。
前述のとおり安価かつ手軽(特殊な調理器具とかが入らない)かつ材料の入手が容易(食べたい時に食べられる)
をめざしつつ、既存のラーメン記事などを読みながら工夫しました。
スープについて。
記事を見る限り、家系ラーメンのスープは鶏ガラと豚骨をに出して作ったものが多いようです。
どちらも入手はなんとかなりますが(それも近所スーパーにはない)面倒ではあるし、価格もそれなりです。
また「出汁をとる」行為は素人には難しいです。失敗するとつらい。ということで代用品を考えました。
大事な構成要素は
・鶏ガラ
→鳥由来 の出汁→鶏ガラスープのもと。楽勝。安い。完璧
・豚骨
→豚肉由来の出汁→牛豚合挽きミンチ。
どん二郎なるものから着想。ようは肉の脂がいるのだと解釈。どん二郎は牛脂を使用していました。のであえて合挽きで行ってみるか。という形。
牛脂の入手が容易なスーパーであれば、牛脂もあると良さそうです。
・野菜
→だいたいの記事によると、野菜の甘みが重要なようでした。こちらも多量の野菜が必要になってしまいます。
ということでコンソメでいいんじゃね?ということでコンソメのもとを使うことにしました。
・あと砂糖。砂糖は美味しいのです。上記甘みもありますが、人の舌は砂糖への反応は敏感です。スーパー安肉も砂糖につけこんでおくと謎のうまさを発揮します(甘いという感じないのに。うまくなるんだすねぇ)
ということで砂糖も適当にぶち込んでおくことにしました。だいたい美味しいものは「砂糖」と「脂」でできている。
ということでスープの着想はこんな感じ。そもそも市販のもとがメインなのでまずハズレはしないでしょう。
ラーメンのたれ
家系ラーメンではかえし。といわれる醤油ベースのタレを使います。
これをスープと混ぜて調整します。いろいろ記事を見る限り、大量に必要で長期間煮込むスープには塩分を加えず、
塩加減はこちらのタレを混ぜ合わせることで調整する様子でした。
なので「醤油」と「塩(醤油だけで合わせるのは難しいかもしれない)」電子レンジに放り込んで軽く熱して塩をとかしておきましょう。
あとついでに砂糖も入れました。タレっていってるし。
スープにぶち込んだらええのでは?という思いもありますし、実際味を調整しながらするならそっちのほうが楽だと思います。
私の場合、小さな子供も含む家族にも振る舞うので、ここで塩分の調整が聞くのはプラスでした。
ニンニク
ここをおろそかにすると味わいが変わってしまいます。
実際今回は味わいが再現度が低くなってしまった要因はこのニンニクと分析しています。
ひとまずチューブでも美味しいですが、可能であれば国産の香りのよいニンニクをすりおろして入れたほうがよいでしょう。
中国産のやっすいやつは「辛い」だけで再現度が薄いです。好みもあると思いますがね。お値段気にしなければ国産ぶち込みましょう。
今度は中国産でやってみます。
麺
材料のなかでも異才をはなっている。と思わしきうどん麺。実際妻にも「ラーメンと行っていたのでは?」といぶしがられています。
ようは特徴的な「極太麺」と麺に含まれる「塩味」を再現するにはうどん麺のほうが都合がよかったんですね。
ということで讃岐冷凍うどんを打ち込むことにしました。
こちらもどん二郎を参考に。あれもうどんですからね。いけると思いました。実際いい感じでしたよ。
何をもって頭が「ラーメン」「うどん」と認識しているのか謎です。
まとめ。
品川出張させてくれ。蒲田とか川崎のへんでもいいよ。
それかふらっとしれっと入れる感じで岡山にないかなー。