令和5年度 春 応用情報技術者試験 データベース問題の雑な解説
社内勉強会用に雑解説。
別に記事に起こさなくてもいいんだけど、起こしたほうがちゃんとまとめるパワーがでる。
- とく順番
まずは回答見よう。ざっとみて無理そうならほかの区分選ぶが吉。
- 読み方
キーワードを拾う。拾え。
序盤。
冒頭3行はストーリ膨らませるためのものだから無視でOK。

重要フレーズ:「従業員の職務区分には管理職、一般職の二つあり」
分類を示すようなものが名にでてるのでメモっておこう。DB上にどう適宜されるかも疑問として持っておくべき。
この分で少なくとも「職務区分」列が存在することわかり、2つあるとのことで列のカーディナリティもわかる。
DBを設計するうえで「どんな種類のデータか」は重要なのでここは確実におさえる。
重要フレーズ:「組織には1名以上の従業員が所属している」
これもカーディナリティに言及しているので重要。
というかここ冒頭3行はいらないけどほかの文書は全部重要。
テーブル単体としてのデータの性質と、テーブル同士の性質がわかる記述はほぼ必須。読み解く。

図は階層のイメージがつかめなかったら抑えとく。KPIうんぬんは説明なのでどうでもいいっす。

数字と方法はWHERE区の条件になりえるので「あーなんかかいとったなー」ぐらいは目を通しておく。
見落としがちな「含めない」系の条件は線を引いておくといい。大体クエリでこのあたりが抜けてるので、ほらやっぱりーってなる。
単純な集計条件を問うこともあるけど、条件あってるのにおかしなーってときは「排除する条件」が足りてないことがほとんど。

図。まーとくときでOK.何回も見返すからしゃーなす。


基本的に「クエリを書かせる」ので、文章から「条件」を引っ張り出しまくる。
1階層目の「NULL」と職務区分のデータ「9999/12/31」は敏感に反応できるといい。
基本的にSQLは「まとめてとる」のでこのあたりの境界に属する条件をどうやって処理するかで悩むから。当然設問もこの辺をおしてくくる。
- 解く
a , b
ER完成させましょう問題。文章からテーブルの関係性を読み取れば解けるはず。
まずは簡単そうなBからいこう。
・よほどの事情がないかぎりテーブルには主キーとなる属性(アトリビュート)があるが、これはない。
・従業員テーブルの属性を見る限り、従業員の情報を格納しておくテーブルであることは推測できる。
・従業員テーブルを「一意に定める」条件が問題文中に見当たらない(あれば大体「一意になる」とかなんとか書いてるから。今回はなし)
以上から、ER図をみて空気よんでちょ。という問題になる。
属性の名称は特に明記がない限り通常問題文中の言葉を使うのが望ましい。
これすごく嫌なんだけど「従業員コード」以外に妥当なキーが見当たらない。
DBではよく「○○コード」(サロゲート)をキーとして持たせる。正直従業員コードが従業員テーブルの主キーじゃなかったら嫌なので。というひどい回答になる。
サロゲート
ナチュラルキーに対して、業務上は意味を持つ値ではないが、システム的に一意な値をとるようオートインクリメントなどで連番を振り、PKとしているテーブルのPKのことをサロゲートキー(代理キー)と呼びます。
a リレーションのカーディナリティ
ここはリレーションを引く以外はないのだけれど。あとはカーディナリティ(1:1、多:1、1:多、多対多)をどうするか。である。
まず多対多はなくなる。設計が壊れてなければ(壊れていることを明示しているERでなければ)そもそも多対多は存在できないから。
あとは問題文中から「組織」と「所属」に関する関係を開いてみていくわけだが、文中に明に2テーブルの関連を明示する記載は見当たらない。

となるとあとは持っている属性から推測していくぐらいしかなかろうて。
組織テーブルを見てみる

組織テーブルのアトリビュートは「所属」テーブルのキーに該当する要素を持っていないため、独立していると考えられえる。
よって組織テーブルは側のカーディナリティは「1」。
役職テーブルを見てみる

外部キーありますね。属性名は微妙にちがいますが、組織テーブルの外部キーとみてよいでしょう。
![]()
外部キーを持ってる側は通常「多」になりすので「1:多(ー>)」になります。
なぜ「外部キーだと多になるの?」ですが、
正規化される前の状態に戻すと納得すると思います。
組織と所属テーブルが1つだった時代は
めちゃくちゃ端折りますが
「従業員コード」
「役職コード」
「組織コード」
「組織名」
でした。従業員コードは主キーなので、同じものは何度もあらわれませんが、
組織コードは複数の従業員コードに同じ値が現れる可能性があります。
そして、
「組織コード」は従業員コードに推移的従属をしているので(従業員コードがわかると組織コードがわかる、組織コードがわかると組織名がわかる)
で、正規化されて「組織」テーブルとしてだされたわけですね。ということで。
c,d
これ質問が悪いよーって感じはあるんですが。JOINの種類を問う問題です。
・絞り込みとしてのINNER JOIN
・母体としてのOUTER JOIN
・重複削除のUNION
このあたりのうち、設問がどこを聞いてるかこたえろ。っていう感じになります。

あとはよしなに・・・パワーかかりすぎて全部解説するの大変ですねこれ。
nkfした後のgrepが意味わからんすぎてムシャムシャして食べた
linux環境でsjisファイルにgrep(日本語)検索しようとして全く謎挙動だったから食べた。
食べられなかった。
<コマンドだけほしい用>
単発式
# ファイルの文字コードを合わせる場合 nkf -Sw sample.sjis | grep "あああ" nkf -[入力オプション][出力オプション] [対象ファイル] | grep [検索文字] # 検索文字の文字コードを合わせる場合 grep `echo "あああ" | nkf -Ws` sample.sjis
find活用grep式
find ./ -type f | xargs -I {} nkf -Sw {} | grep -n "漢字"入力オプションにファイルの文字コード、出力コードにgrepに使われる検索をつかう。
つまずきポイント
・入力と出力の両方のオプションがある。ここの指定をミスってるとうまく行かない。
・grepは文字コードがシステムに依存している。らしい。echo $LANGで使ってる文字コードを調べる。
・findでのパイプ経由がくせもの
grep -a `echo "あああ" | nkf -Ws` sample.sjis
これでもいい。入力のguess(デフォルト)を信じないところが重要だとおもっている。
わかってるなら指定しておいたほうが無難。
find ./ -type f | nkf -Sw | grep -n "漢字"
これはうごかない。findの結果を渡してしまうのでファイルとしてではなくて単純に文字列としてnkfしてるっぽい。
やってみたけどよくわかりません。よくわかりませんがnkfにIN/OUTのオプションがあるのがわかったので、良しとします。
<参考にさせていただきました>
atmarkit.itmedia.co.jp
sysfrontier.com
qiita.com
ちょろっと人間感知できないかchatGPT(3.5)と仕事してみた

import cv2 # USBカメラからの映像を取得する cap = cv2.VideoCapture(0) # 人間検知用の分類器を読み込む human_cascade = cv2.CascadeClassifier('haarcascade_fullbody.xml') while True: # 映像を1フレームずつ読み込む ret, frame = cap.read() # グレースケールに変換する gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 人間検知を行う humans = human_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30)) # 人間が検知された場合は、矩形で囲む for (x, y, w, h) in humans: cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2) # 結果を表示する cv2.imshow('frame', frame) # キー入力を待つ if cv2.waitKey(1) == ord('q'): break # プログラムを終了する cap.release() cv2.destroyAllWindows()
プログラムもくれるし、解説もくれる。やさしい

これだと動かないから追加質問。前提とかそーゆーのをすっ飛ばすのかな。今回だとモデルファイルが明らかに足りない。

ぐっどー。とりあえずこれで動いた。fullbodyなので全身だった。
顔だけでいいから〜とおもってモデルは差し替えありとか、細かい調整はしたけど動くものができて感動した。
感想
ある程度質問は考える必要はあるし、結果をちゃんと検証してあげないといけないけど、
完全ゼロベースから作ろうとおもたらすごいらく。今のところ強いGoogle検索感。
検索ワードすらまともに絞れないような状態のときなんかはめっちゃ便利だと思う。つよい。
amazonのwishlistがほしくて。
ほしい物リストなんだからほしいだろ?
とりあえずJson形式で変換できるライブラリまではできた。
スクリプトID.
1A57eCBGZOYS2kpyxeXF6C_2S1mts6jJyL_gV3hfRYt4Xl1oFy66j8Lyq
GIT
https://github.com/yukiYamada/AmazonWishlist
参考にしたサイト
GASを利用してWebスクレイピングをやってみよう | エクスチュア株式会社ブログ
Google Apps Scriptでプライベート関数を宣言し、「実行する関数を選択」に表示させない - 毎日へっぽこ
GAS│ライブラリの作り方と使い方 | CGメソッド
<ゆるゆる あどべんとかれんだー2021「~toAWS」>6日目|Azure to AWS
3,4,5日目なんてなかった。いいね。
たいそうなタイトルになったけどすごーく浅いところで止めるよ。
目次
- はじめに
- Azure Fundamentals(AZ-900) ⇒ AWS AWS Certified Cloud Practitioner
- Azure portal ⇒ AWS management Console
- コンピューティング AZURE ⇒ AWS
- おわり。
はじめに
ざっつーに比較してますが。
そもそも同一じゃなかったり、やれることはやれるけど全然違うものだったりします。
ある程度どちらかを知っている人が新しく習得する足掛かり。程度かもしれない。
それにしたって概念ごと吸収したほうがいい気もするので、下手に比較しないほうがいいかなーと思ってます。
Azure Fundamentals(AZ-900) ⇒ AWS AWS Certified Cloud Practitioner
共に初級レベル。というか入門というか。の認定試験ですね。
サービスの突っ込んだ内容というよりは、Azureだったり、AWS
AWSだったりの概念。というかクラウドそのものだったりの知識を問われる形になるかなーとおもいます。
あとはそれぞれの「クラウド」の解釈だったりとかかな。
AWSの方はこんな感じですね。
AWS Certified Cloud Practitioner は、AWS プラットフォームの基本的な知識をお持ちの方を対象としています。この試験を受ける前に、以下のことをお勧めします。
AWS クラウドに 6 ヶ月間触れている
IT サービスのベーシックな知識と、AWS クラウドプラットフォームにおけるそれらのサービスの使用に関するベーシックな知識がある
AWS のコアサービスとユースケース、課金、料金モデル、セキュリティコンセプト、クラウドがビジネスに与える影響についての知識がある引用
https://aws.amazon.com/jp/certification/certified-cloud-practitioner/
Azureのほうは
クラウドの概念に関する説明
Azure の主要サービスに関する説明
Azure のコア ソリューションおよび管理ツールに関する説明
一般的なセキュリティ機能およびネットワーク セキュリティ機能に関する説明
ID、ガバナンス、プライバシー、およびコンプライアンス機能に関する説明
Azure Cost Management およびサービス レベル アグリーメントに関する説明
引用
https://docs.microsoft.com/ja-jp/learn/paths/az-900-describe-cloud-concepts/
どすこい。
Azure portal ⇒ AWS management Console
操作用のGUIですね。
Azureの方は
Azure portal は、コマンドライン ツールに代えて使用できる、Web ベースの統合コンソールです。 Azure portal を使用すると、グラフィカル ユーザー インターフェイスを使用して Azure サブスクリプションを管理できます。 次の操作を行います。
簡単な Web アプリから複雑なクラウド デプロイまで、すべてを構築、管理、監視することができます。
リソースを整理して表示するカスタム ダッシュボードを作成できます。
最適なエクスペリエンスを提供するアクセシビリティ オプションを構成できます。
引用
https://docs.microsoft.com/ja-jp/learn/modules/intro-to-azure-fundamentals/what-is-microsoft-azure
ということなんで、GUIで全部まかなえるっぽいです。触ったことないんですけど。
AWSのほうはさらーっとしたところは触れるんですが、がっつり使おうと思うとCLI(コマンドラインインターフェース)
なりを使わないとやりにくいかなーというのが感想です。
コンピューティング AZURE ⇒ AWS
数が多い。でかめにいく。
| Azure | AWS | 説明 |
|---|---|---|
| Azure Virtual Machines | EC2 | クラウド上の仮想まっすぃーん。VM細かいところはだいぶ違うと思うけど、浅いところは大差ないかな |
| Azure Kubernetes Service | EKS | k8sのマネジメントサービスかな。 |
| Azure Container Instances | ECS | これだいぶ違うんじゃないかなー。マネジメントなコンテナのオーケストレーションをサポートするぐらいしか類似ない気がする |
| Azure Functions | AWS lambda | イベントドリブンな関数実行的な。これは深いところは一緒な気がするけど、環境周りとかその辺は全然ちがうだろうなぁ |
仮想マシンはドキュメント
https://docs.microsoft.com/ja-jp/azure/virtual-machines/
ざっとよんでもなんかAWSと似たような感じで・・・
オート―スケールもできるし、リザーブドなインスタンスもあるし専有ホストもあるっぽい。もちろん違いはあるんだろうけどちょっと難しそう。
料金的な差もあるので検討するときはここは注意かなーと思う。
Functionsとlambdaもまーにてるような。Durable FunctionsとStepFunctionsがついになってんのかなーという気もする。
ここは特に動作仕様しだいでは単純に「同じ」というわけにもいかんところが多いと思うので、危ないよなーという感じ。
おわり。
つかれた。このシリーズで明日もなにか。。。
似たような名前で違うことしたり同じことするから混乱するね。
<ゆるゆる あどべんとかれんだー2021「~toAWS」>2日目|csv(excel) to AWS
なんとか書く気力がわいたので2日目いってみよー。
目次
csv to AWSってなにするの。
s3にcsvほうりこんでathena(あてな)でクエリでも叩いてみませう。てな具合でs。
s3については1日目に軽く説明したよ
括弧excel的な奴はようするに、RDBMSもつかわずCSVでなりEXCELなり管理しているとしていて、
さらっとAWSにあげてみっか。というはなし。
ただクエリとか出てくるので使用感は違うかなーという気がします。
quickSiteとかその辺と組み合わせないとExcelの使用感は出ないと思う。
でかるーく検索したらコーユーのがヒットするんですよね。
aws.amazon.com
が、これはやらない。やってもよかったけどやろうとおもったこととはちがってるからだね。
検索の順番とかやることが固まってなかったらしたかもしれない。3日目に回す可能性もあるかな。
csv(excel) TO AWS
もとになるCSVを取ってくる。
こーゆー時はいつも厚労省が公開してるCSVをなぜか参照してるんだ。
きょうもここからオープンデータ|厚生労働省
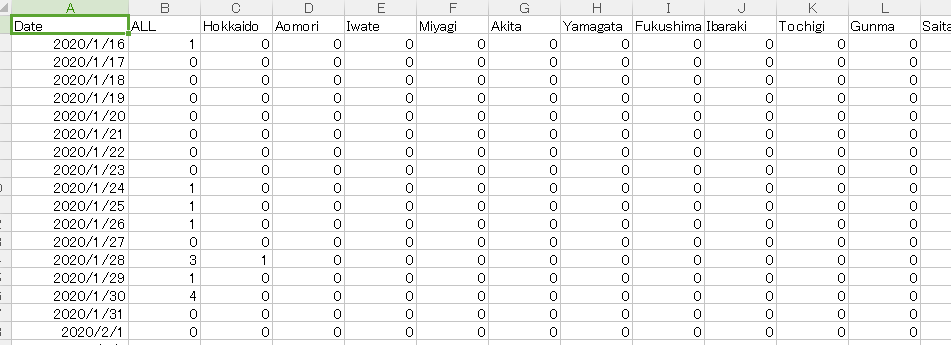
○新規陽性者数の推移(日別)のCSVをもってきてつかうよ。
中身はこんなので。日別データっす。
 gyazo.com
gyazo.com
s3にぶちこむ。
ぶち込むだけ。今回は1日目みたいにアクセス制限は気にしなくていい。
※全部AWSコンソールでやるので、ログインしているユーザーにアクセス権限(ポリシー)が付与されていればよいのだ

AWS Glueで正規化(正規化であってるよね???)
生のCSVはそのままクエリを発行するには不都合がゴリゴリあります。
ということでGlueで正規化してCSVをデータベースとして取り扱えるようにします。
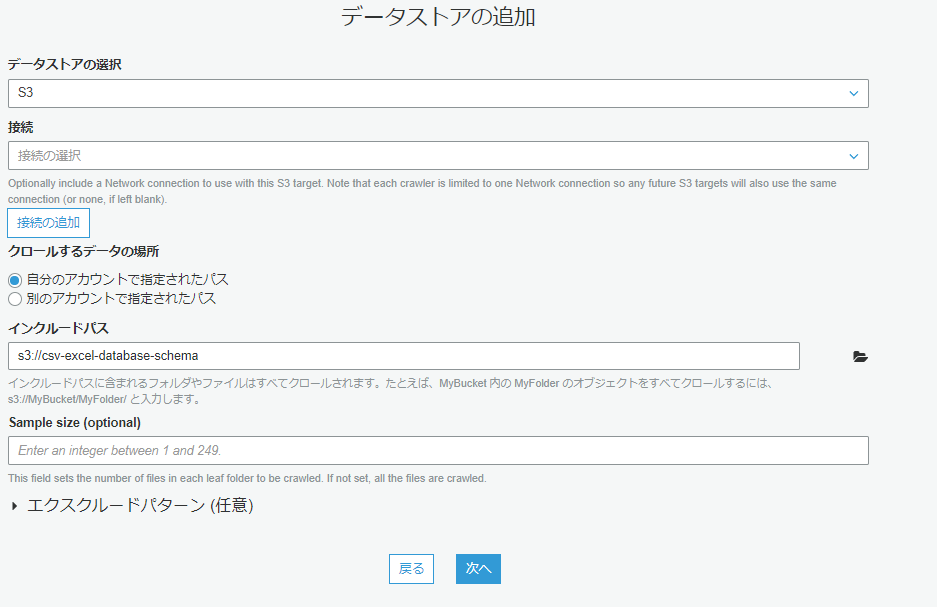
クローラをセットアップしてS3を巡回(今回はオンデマンド設定で1回だけしかうごかさないですが)
させて、テーブル情報を検索させます。
 gyazo.com
gyazo.com
 gyazo.com
gyazo.com
 gyazo.com
gyazo.com
さっきつくったS3をえらぶ
 gyazo.com
gyazo.com
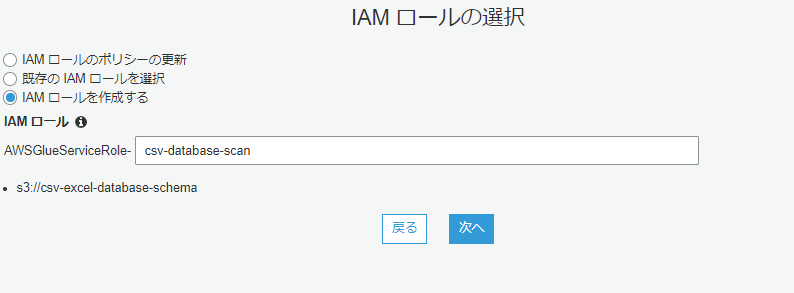
ロールはもともとあればそれを使えばいいし、なければ↑のように。
 gyazo.com
gyazo.com
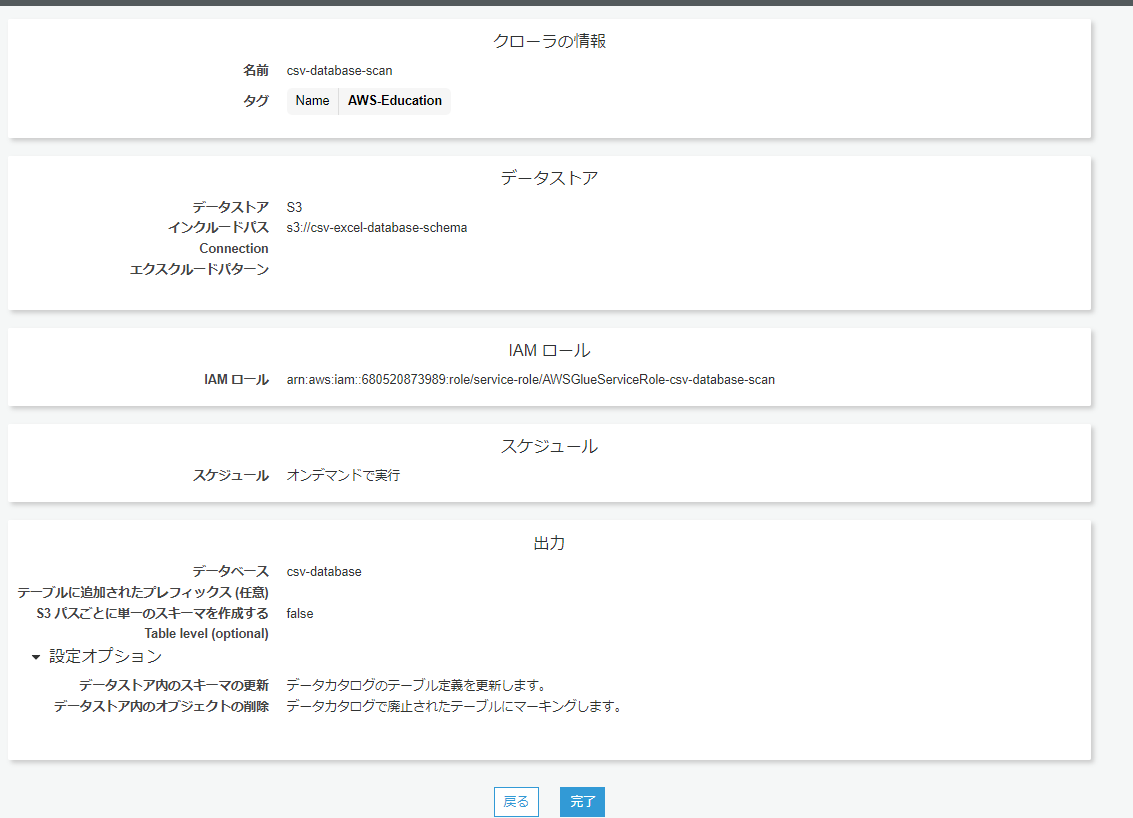
こんなかんじかな
できたら実行します。1分ぐらいかかってますが。
 gyazo.com
gyazo.com
 gyazo.com
gyazo.com
それなりにできてるきがする。
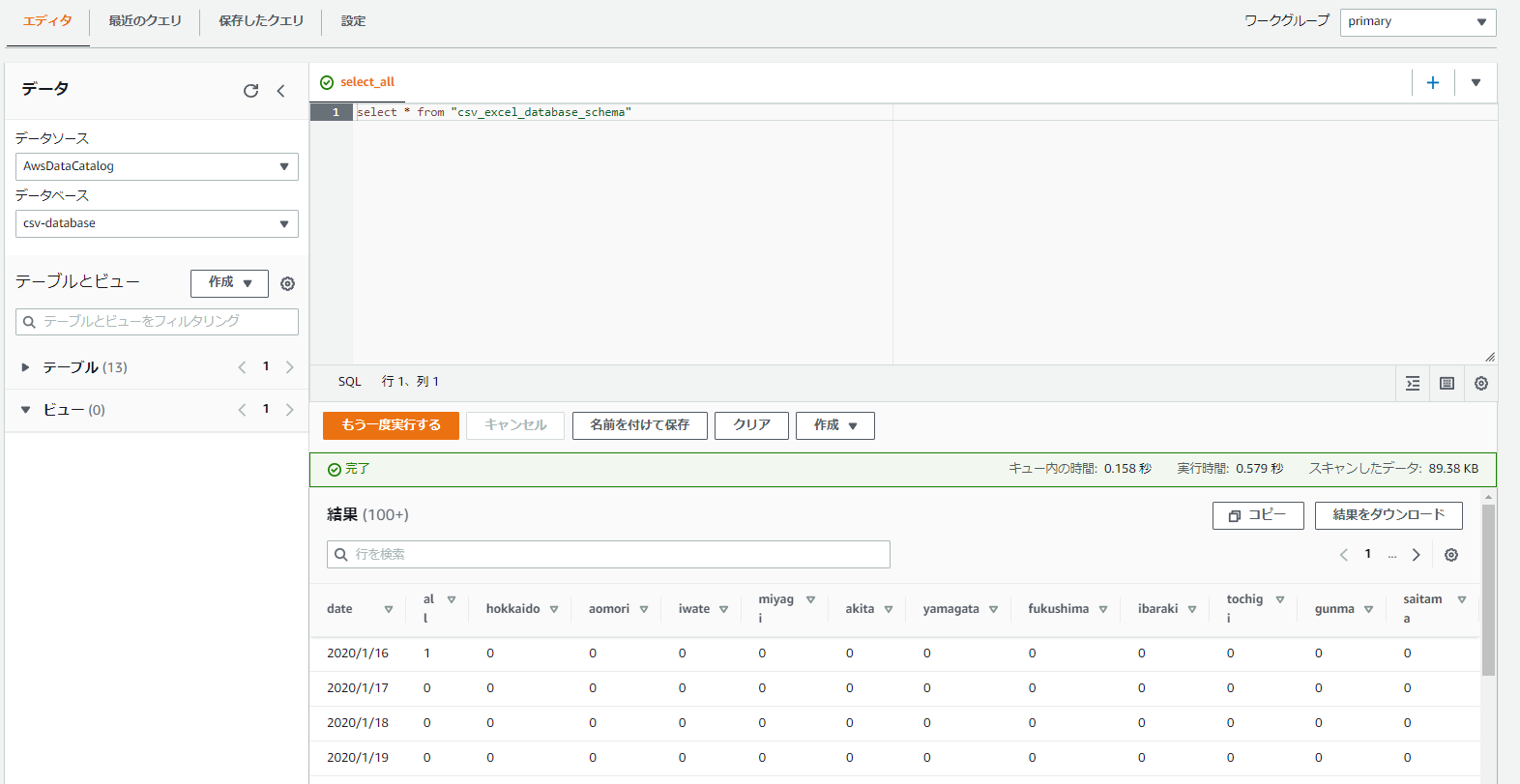
Athenaでクエリを発行する。
おらぁ!!!
 gyazo.com
gyazo.com
おわり
なんじゃこれかん。たぶんこの状態だとオンプレでCSVをEXCELでよませるなり、
適当にスプレッドシートにでも物故んだほうが使いやすい。
athenaにJDBC経由でアクセスしたり、gateway開けるとか。なんかその辺しないと「うーん」ってなる。
なってる。
ちょっとパワーがたりねぇなぁ。ちょっとじゃねぇかもしれんけど。
ETLとかつかって String -> Dateとかもやりたかったけどちょっとよくわからんかったからやってない。
※よく見ると日付のはずの列が文字列になっているのだ。CSVだと日付のフォーマットが正規化されてないから文字として扱われちゃっている。
わかんないこと多いね。
<ゆるゆる あどべんとかれんだー2021「~toAWS」>1日目|WEB Site to AWS
目次
何日つづくかわからんけど1日目。
はじめてやってみる。ことしは「toAWS」なにかをAWSでやってみる的なフワッとしたやつです。
きょうなにやーるかな
htmlを s3 で公開してみよう。ぱんぱかぱん。
AWSのアカウントを作ってからすぐにでも試せるこの構成。
しんぷるすとれーじさーびす。ということでAWSのクラウドストレージのひとつといってもいいかもしれない。
特徴は格納対象(ファイルということにしますよ。便宜上)のものを「オブジェクト」としてとりあつかって、
なんでも(1ファイル最大5TB)「オブジェクト」としてファイルの種類はいません。
圧縮ファイルでも画像でも、テキストでもなんでもおK。暗号化やバージョン管理まで完備しています。
「ただの箱」以上にいろんな機能があるんですがその中のひとつに「静的WebSiteの公開」というものがあります。
S3に格納したファイルをつかってWebサイトとして公開できるというような形です。
てじゅん
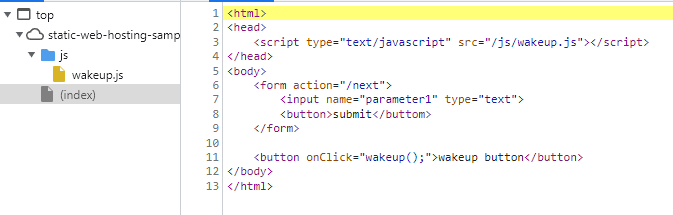
公開のhtmlをつくる。
 gyazo.com
gyazo.com
indexようのページと、移動先とjs。だいたいこれだけできればええでしょ。
index.html
<html> <head> <script type="text/javascript" src="/js/wakeup.js"></script> </head> <body> <form action="/next.html"> <input name="parameter1" type="text"> <button>submit</buttom> </form> <button onClick="wakeup();">wakeup button</button> </body> </html>
next.html
<html> <body> <p>次のページです。</p> <body> </html>
js/wakeup.js
function wakeup(){
alert('アラートだよ');
}やる気の感じられるよいソースだとおもう。
コンソールにログイン。
お好きなアカウントでどうぞ。
公開用のバケットをつくる。
s3はたくさん入れ物をつくれるんだけど。入れ物の一番でかい単位のことを「バケット」といいます。
 gyazo.com
gyazo.com
つくるどー
 gyazo.com
gyazo.com
つくったどー。なまえはなんとなくだどー
ファイルをアップロードする。
 gyazo.com
gyazo.com
つくったファイルたちをぶち込むどー
静的WEBホスティングを有効にする。
バケットのプロパティをいじいじして機能を有効にします。
 gyazo.com
gyazo.com
ここの
 gyazo.com
gyazo.com
下の方のここから
 gyazo.com
gyazo.com
空気読む感じで行ける気がしますが。index.htmlはさっきつくったファイルです。
バケットにアクセスして参照しようとするファイルを宣言します。
http://~~~~/
ってアクセスされたときに渡すデフォルトのファイル名という感じかな。
~~~~はバケットへのアクセスURL(後述)が入ります。
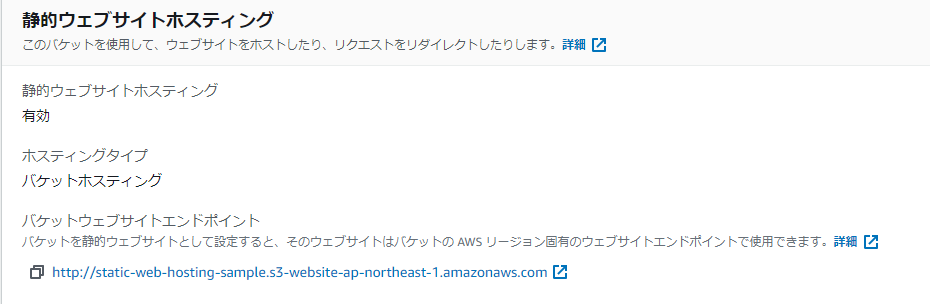 gyazo.com
gyazo.com
すぐできる。これの下のほうのやつがさきほどのアクセスURLです。
接続確認する。
ということで早速リンク踏んでみましょう。
 gyazo.com
gyazo.com
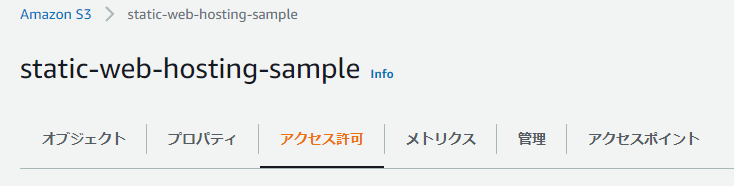
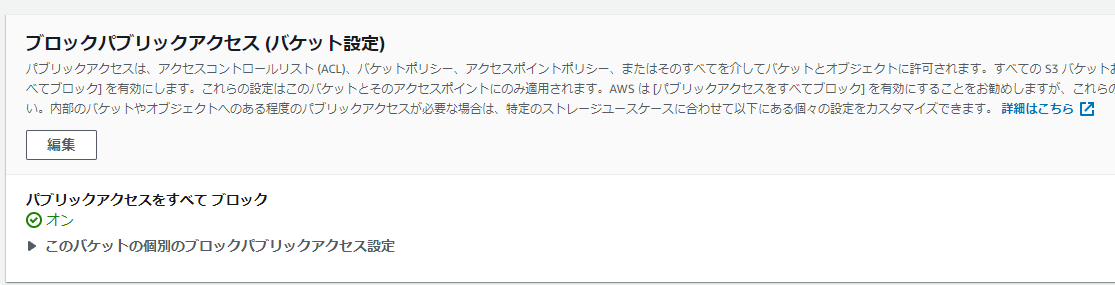
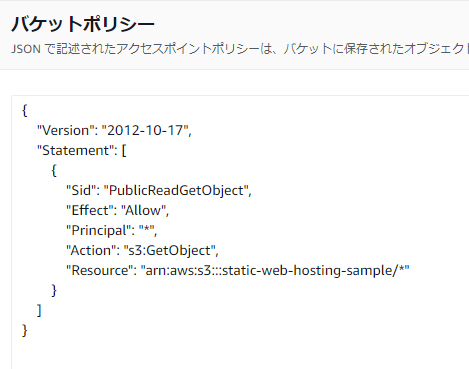
ダメ―。じつはデフォルトだと外部からのアクセス権限ないので開放します。
詳しくは参照されたし。
外部に公開するということは不特定多数の人がアクセスできるようになるということで。
この辺りはちゃんと理解して自己責任マックスで設定してください。
docs.aws.amazon.com


おわり
すんなりいけるかとおもったらまーたせきゅりてぃで阻まれてしまった。
安全側に倒してくれているからうれしいということにしておこう。
WEBサイトようのサーバー立ち上げて、いろいろゴニョゴニョすることを考えると金銭的にも管理的にも大分恩恵が大きいです。
大きくなると思います。もちろんアクセス数とかSLAなりなんなりで考慮しないといけないこともあると思いますが。
あしたなにするかな。つかれた。これ毎日やってるひとすごいわ・・・